Road Segmentation

Introduction
This is the course project of CS433 Machine Learning (Fall 2021). In this project, our task is to perform semantic segmentation to separate roads from satellite/aerial images. The goal is to train a machine learning model which takes an image as input and outputs a binary mask, indicating the road and background. The model performance is evaluated by a patch-wise approach. The output mask is divided into 16x16 patches, where a patch is recognized as a road class if 25% of the pixel are predicted to be positive.

Method
Data preparation
The provided dataset consists of 100 images with groundtruth masks for training and 50 images without groundtruth mask for testing.
To perform data augmentation, we adopted random flipping, cropping, and rotation. Also, since we used pretrained model that trained on ImageNet, the input images are normalized with the mean and standard deviation of ImageNet.
Models
We tried several conventional deep learning models for this work, including a CNN consist of 2 fully-connected layers (the baseline provided by the TA), U-Net, TernausNet, and Deeplabv3. We also invented a 2-stage network, where we connected a U-Net in the end of the DeepLabv3 to try to eliminate the false-positive prediction.
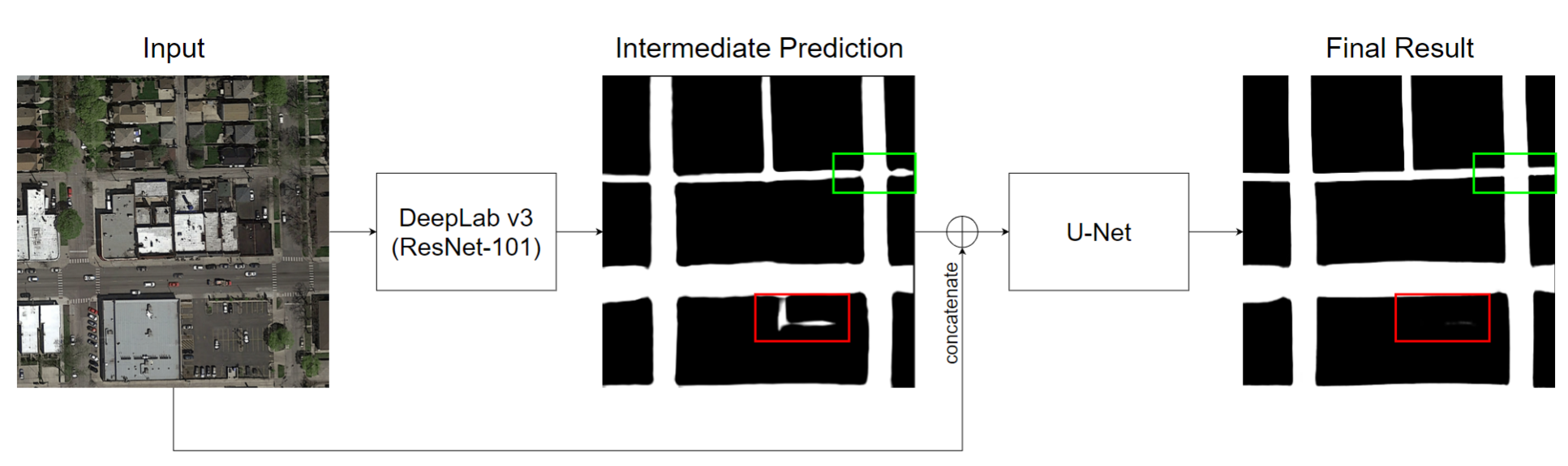
Loss function
For the loss function, the most trivial one is the binary cross entropy. Other than that, we tried dice loss and patch-wised binary cross entropy, since the data are a little bit imbalanced and the final evaluation was based on a patch-wised approach.
Training
When training, 90 images are used for training and 10 images are used for evaluation.
After the normal training process is converged, we also tried to fine-tune the model with all 100 images for a fixed number of epochs. Although we got a slightly higher F1 score and Accurarcy, it is almost identical that the difference can be igonred.
Results
Here is the qualitative and quantitative result of different models (combined with different loss function if stated). On the leaderboard, we got 0.922 F1 Score and 0.958 Accurarcy, making us the 4th place among 137 teams.

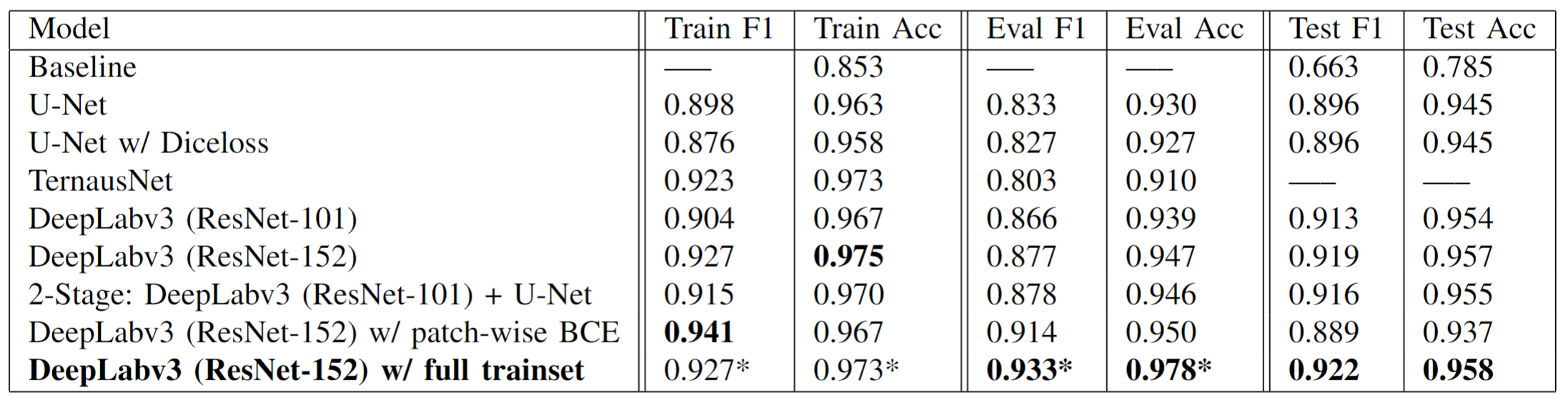
The numbers with * in the last line of the table indicates that the value is not comparable with others since the training data is different and the validation data is used for training in that case.